From 40 Hours to 6: Building Seven Cognitive Specialists for Government Tender Proposals
ProposalForge reduced government tender response effort from 40 hours to 6 at Temus. The architecture draws on a single principle applied at three levels: research agents, a Quality Engine, and QC rules, each split by cognitive mode.

Why decomposing by cognitive mode, not document section, unlocked quality and speed simultaneously
ProposalForge reduced government tender response effort from 40 hours to 6 at Temus. The architecture draws on a single principle applied at three levels: research agents split by cognitive mode, a six-director Quality Engine split by evaluation mode, and QC rules split between deterministic and semantic verification. A closed feedback loop translates each Quality Engine review into pipeline-level improvements, so every proposal the system generates makes the next one better. This case study traces how six iterations of failure led to that architecture, what the Quality Engine's board-of-directors model looks like in production, and why domain expertise shaped every design decision more than engineering knowledge alone.
| Layer | Technology | Role |
| LLM | AWS Bedrock | Claude Opus (planning, writing), Haiku (vision), Titan Embeddings v2 |
| Frontend | Next.js 16, React 19, TypeScript | Tailwind CSS, Shadcn UI, real-time pipeline monitoring |
| Backend | Python 3.12, FastAPI | Pipeline orchestration, WebSocket events, REST API |
| Vector DB | ChromaDB (SQLite) | RAG knowledge base: 2,027 section chunks + 179 captioned images |
| Auth | AWS Cognito | OAuth/JWT, admin whitelist |
| Diagrams | D2, Mermaid | D2 via Playwright, Mermaid via mermaid-cli |
| Storage | EFS (prod) | File-based by design: YAML config, JSON state, no relational DB |
| Deployment | Docker, ECS Fargate | GitLab CI pipeline, ECR registry |
The 40-Hour Tender
Forty hours, two hundred pages, and no margin for error
Every government or enterprise tender carries the same implicit arithmetic: a proposal team will spend the better part of a working week, sometimes longer, transforming a dense requirements document into a submission that must be comprehensive, compliant, and compelling. The documents themselves routinely span 200 to 400 pages, threaded with compliance frameworks (IM8, ISO 27001, PDPA) whose requirements nest inside one another. A single overlooked clause can disqualify an otherwise strong bid. I had watched this cycle repeat for months, senior consultants burning their highest-value hours on formatting tables, cross-referencing appendices, and reconciling terminology across sections, while missed deadlines meant forfeited revenue and inconsistent quality meant losing to competitors who simply executed the process more reliably.
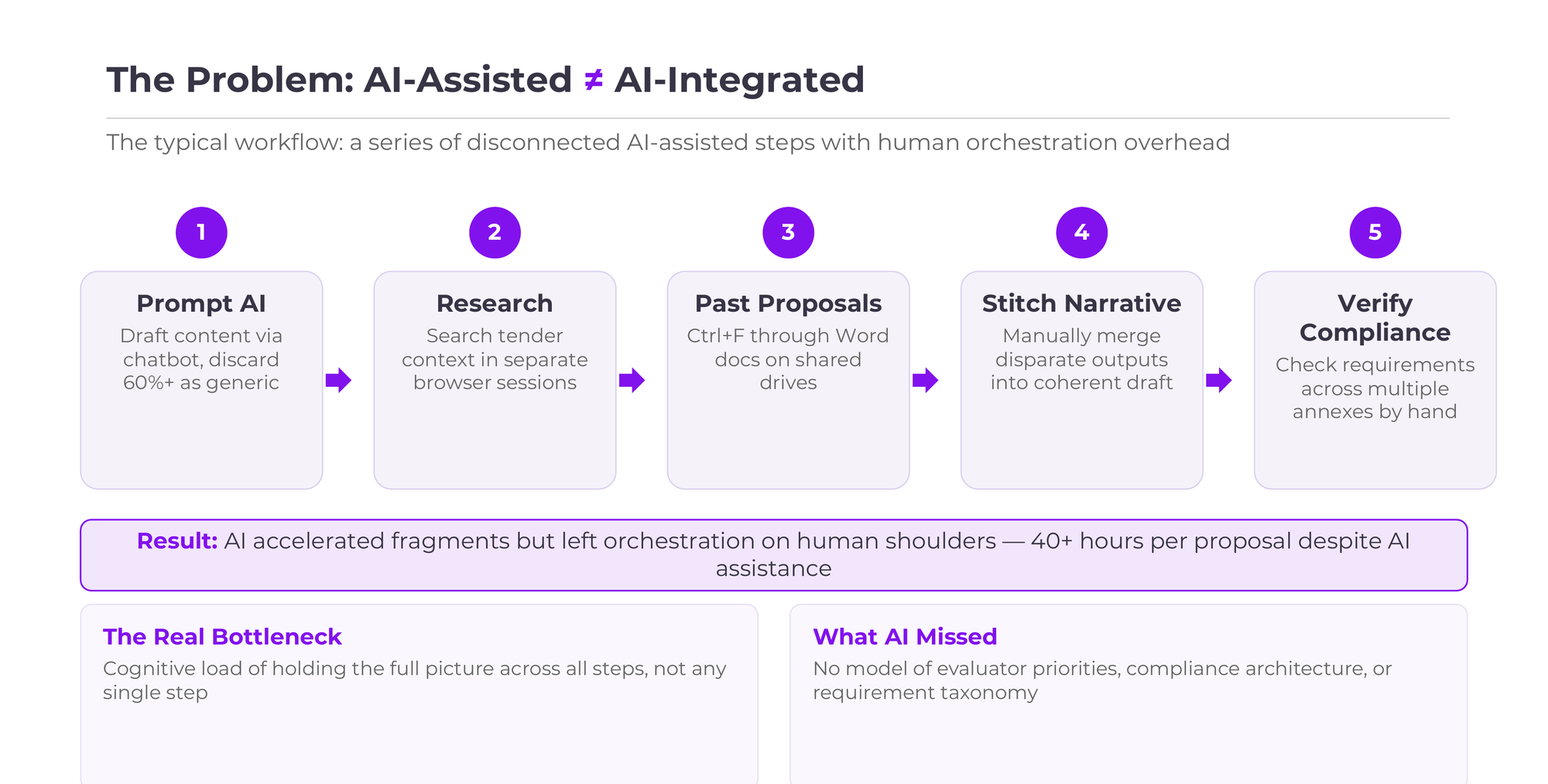
The challenge ran deeper than document length
What made tender writing so resistant to shortcuts was its layered cognitive demand. A single proposal required capabilities that rarely coexisted in one person:
- Deep analytical reading to extract evaluation criteria buried across hundreds of pages
- Domain expertise to craft evidence-based responses grounded in genuine project history
- Compliance verification to confirm that every mandatory requirement received explicit treatment
- Editorial consistency to maintain uniform terminology, tone, and formatting across sections written by different contributors
These were not sequential tasks; they overlapped, creating a web of dependencies where a change in one section could cascade through a dozen others. The difficulty was not merely volumetric. It was structural. The work demanded multiple distinct cognitive modes operating in parallel, and that demand exhausted even the most experienced writers.
Important: The bottleneck was not writing speed; it was the number of different analytical disciplines a single proposal demanded simultaneously.
Why One Big Prompt Fails
A single prompt asked to "write a proposal" failed the same way a single generalist would
My first instinct was the obvious one: feed the tender documents into a large language model and prompt it to produce a proposal. What came back read like a brochure. The output was vague, structurally shallow, and disconnected from the actual tender requirements. It mentioned compliance frameworks by name without demonstrating how they would be satisfied. It could not distinguish between a requirement that demanded a detailed technical response and one that needed a simple acknowledgement.
Through iterative discovery, where I generated proposals against real tender documents and compared them section by section against winning submissions, I identified that the root cause was not prompt quality. The problem was cognitive. A single prompt was being asked to perform at least four fundamentally different reasoning tasks simultaneously:
- Research: extracting and cross-referencing requirements scattered across hundreds of pages
- Compliance mapping: verifying alignment with regulatory frameworks such as IM8, ISO 27001, and PDPA
- Evaluative reasoning: weighing which claims needed evidence and which needed brevity
- Quality control: enforcing consistent terminology, formatting, and factual accuracy
When merged into one prompt, these modes competed for attention within the context window. The model would prioritise fluency at the expense of compliance depth and technical specificity.
Key Takeaway: The problem was not intelligence; it was cognitive mode-switching. Asking one agent to research, evaluate, and quality-check simultaneously produced the same failure as asking a single generalist to do the work of an entire proposal team.
Past proposals held institutional knowledge the system could not access
Winning proposals are not written from scratch. Experienced teams draw on a corpus of proven content: narrative structures that scored well, technical descriptions refined over multiple bids, diagrams that conveyed complex architectures clearly. This institutional knowledge represented years of competitive refinement.
My initial approach to leveraging this corpus, extracting text directly from DOCX files, produced shallow results. Raw text extraction stripped away semantic structure: section hierarchies collapsed into flat strings, table relationships dissolved, and visual assets vanished entirely. The writing agents, deprived of this context, produced content that was disconnected from the firm's proven strategies and established voice.
Cascading failures across pipeline phases turned every improvement into a regression risk
As I moved beyond monolithic prompting toward a multi-phase pipeline, a new class of problem emerged. The pipeline's phases were coupled through mutable configuration: one phase's research output programmed the structure that later phases consumed. A seemingly minor change to how a research agent formatted its findings could silently break assumptions in the planning, writing, or quality control phases downstream. Debugging was exceptionally difficult. Errors compounded across agent turns, and by the time a defect surfaced in the final output, the originating cause might sit three phases earlier.
Each of these 40-hour proposals represented not just labour but revenue at stake; firms that submit generic or non-compliant responses do not win contracts. The interconnected failure modes, shallow output, inaccessible institutional knowledge, and fragile pipeline coupling, meant that fixing any single problem in isolation produced minimal improvement. The challenges were structural, not incremental.
Fractal Decomposition: Agents by Cognitive Mode
Specialised agents mirror how experienced consultants actually divide analytical labour
My breakthrough came from observing how experienced proposal teams at Temus divide labour: one person owns compliance mapping, another extracts win themes, a third structures sections against evaluation criteria. They split work not by document section but by how they think. I call this method human-derived agent strategy design. I observed senior consultants during live tender responses, mapping not what they wrote but how they reasoned. A compliance analyst reads a tender document with a fundamentally different cognitive posture than a competitive strategist reading the same pages.
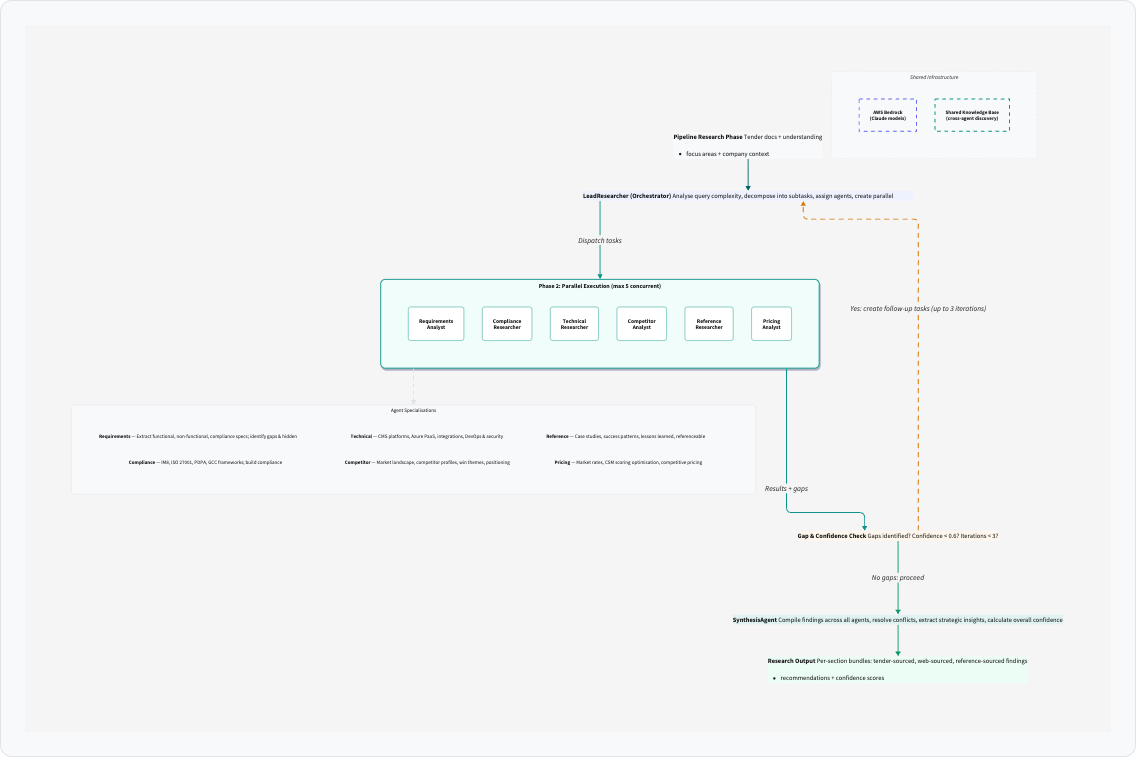
I encoded these distinct reasoning modes into seven specialised research agents (LeadResearcher, RequirementsAnalyst, ComplianceResearcher, TechnicalResearcher, CompetitorAnalyst, ReferenceResearcher, PricingAnalyst), each with explicit analytical personas, scope boundaries, and structured JSON output contracts. This produced agents whose outputs were consistently deeper within their domains than any single generalist prompt could achieve.
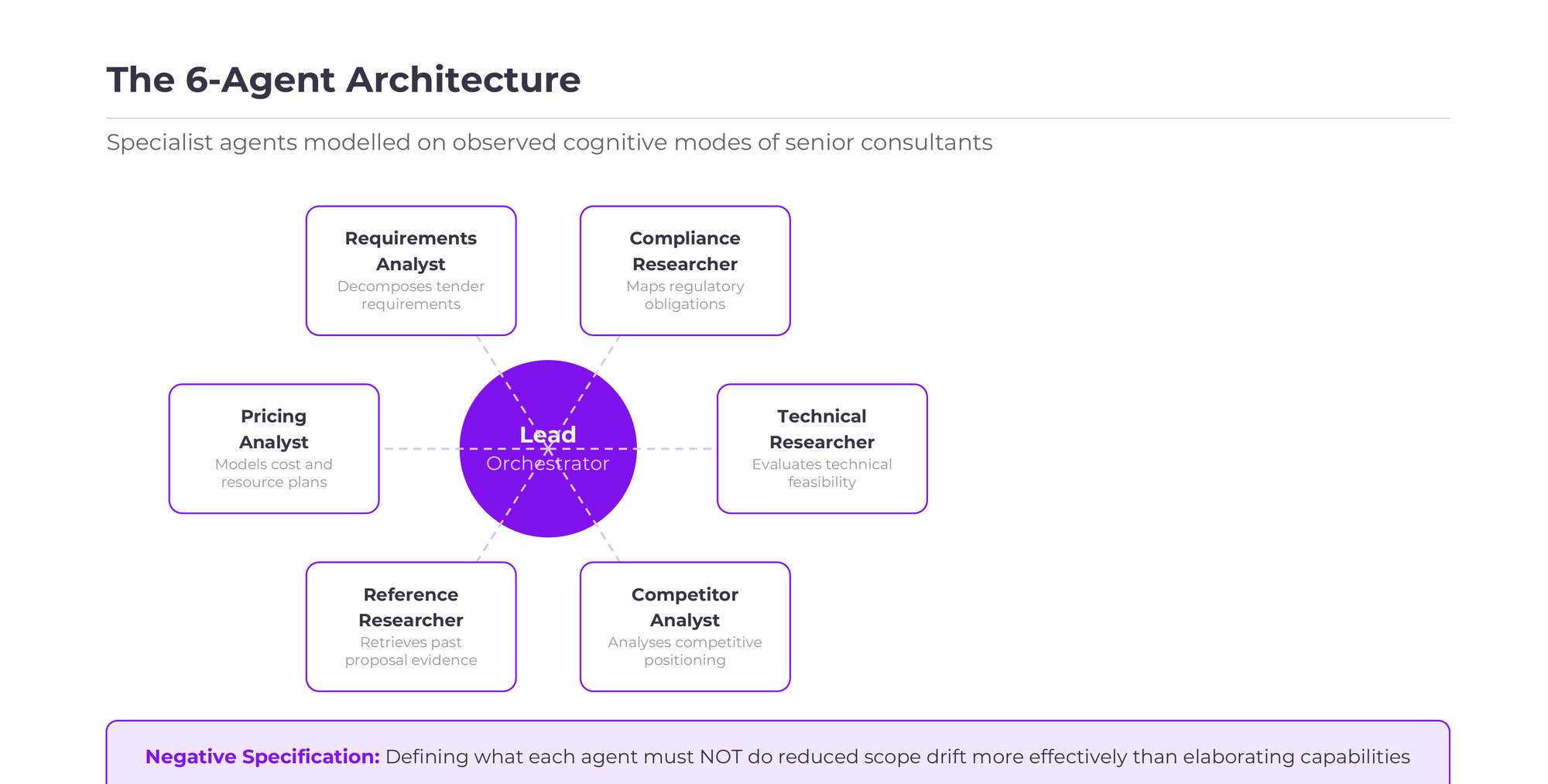
The critical validation came when I initially merged technical and competitive research into one agent. Both domains suffered because the reasoning approaches conflicted. Clear negative boundaries, telling agents what NOT to do, improved performance more than positive instructions.
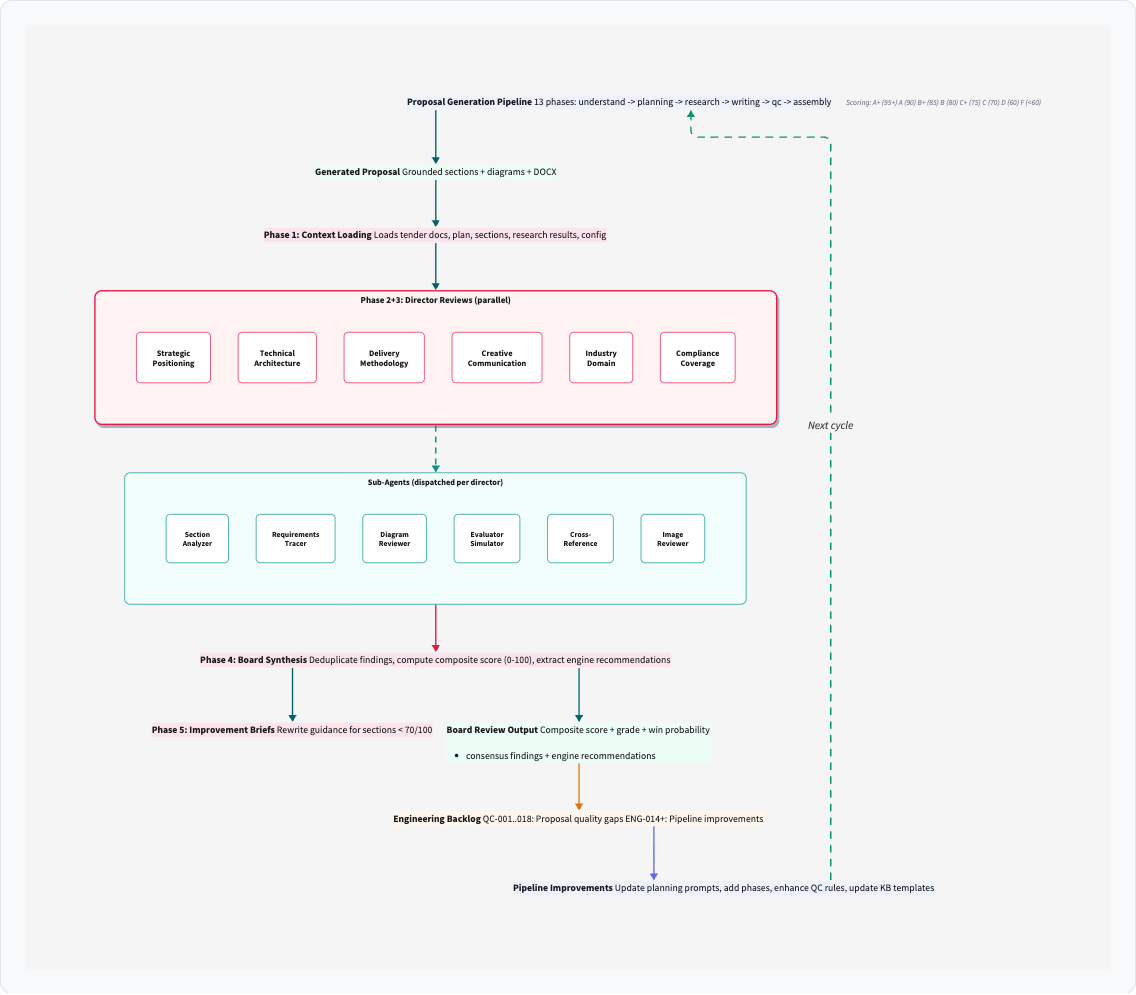
Key Takeaway: The decomposition principle applies at three fractal levels: research agents decomposed by cognitive mode, QE directors decomposed by evaluation mode, and QC rules decomposed between deterministic and semantic verification. This is an architectural principle, not an implementation detail.
The pivot from shallow document extraction to semantic retrieval with cached visual assets was the single biggest quality improvement
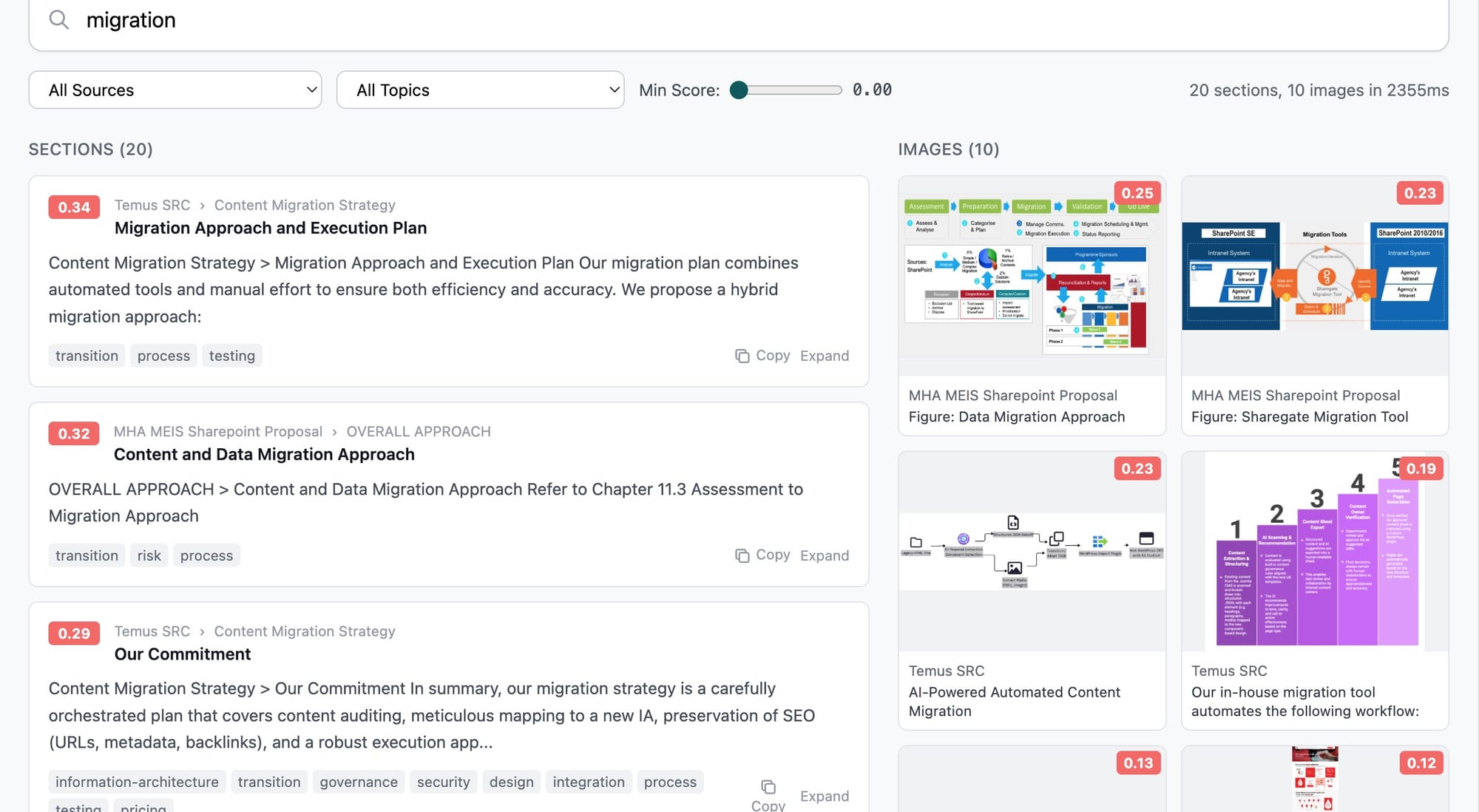
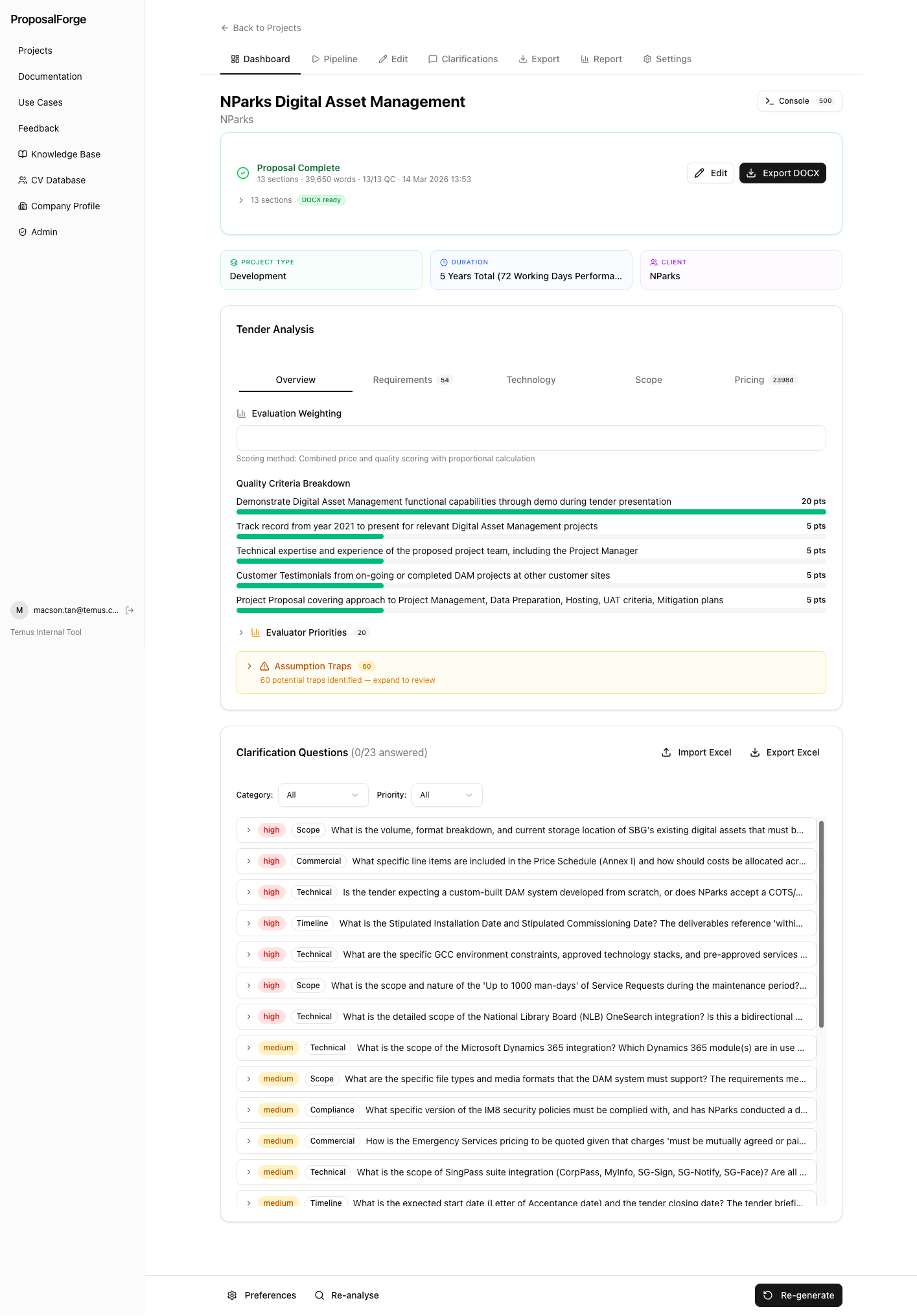
I built a RAG-based institutional knowledge system using ChromaDB (backed by SQLite) and Amazon Titan Text Embeddings v2 to embed narrative sections and images from past reference proposals. The method, image caption caching via vision model, solved an unanticipated problem: reference proposals contained diagrams and screenshots that were critical evidence for claims, but raw DOCX extraction treated them as opaque binary blobs. I ran each extracted image through Claude Haiku's vision model to generate semantic captions, then cached those captions alongside the embeddings. This meant writing agents could search for "network architecture diagram showing zero-trust perimeter" and retrieve an actual diagram from a previous proposal.
For visual selection, I implemented a two-stage pipeline: a keyword pre-filter narrowing to roughly 25 candidates, followed by LLM semantic ranking that selected the top 8 per section. Pure semantic search returned too many marginally relevant results, so the keyword pre-filter constrains the candidate set cheaply before the LLM applies expensive but accurate judgment on a manageable subset.
The Quality Engine applies the same decomposition principle to evaluation
The cognitive decomposition did not stop at research. I structured a Quality Engine as a board-of-directors model with six parallel directors, each representing a distinct evaluation lens. After generation, the QE runs the proposal through all six directors in parallel, producing a composite score (here, 70/C+) with per-director breakdowns:
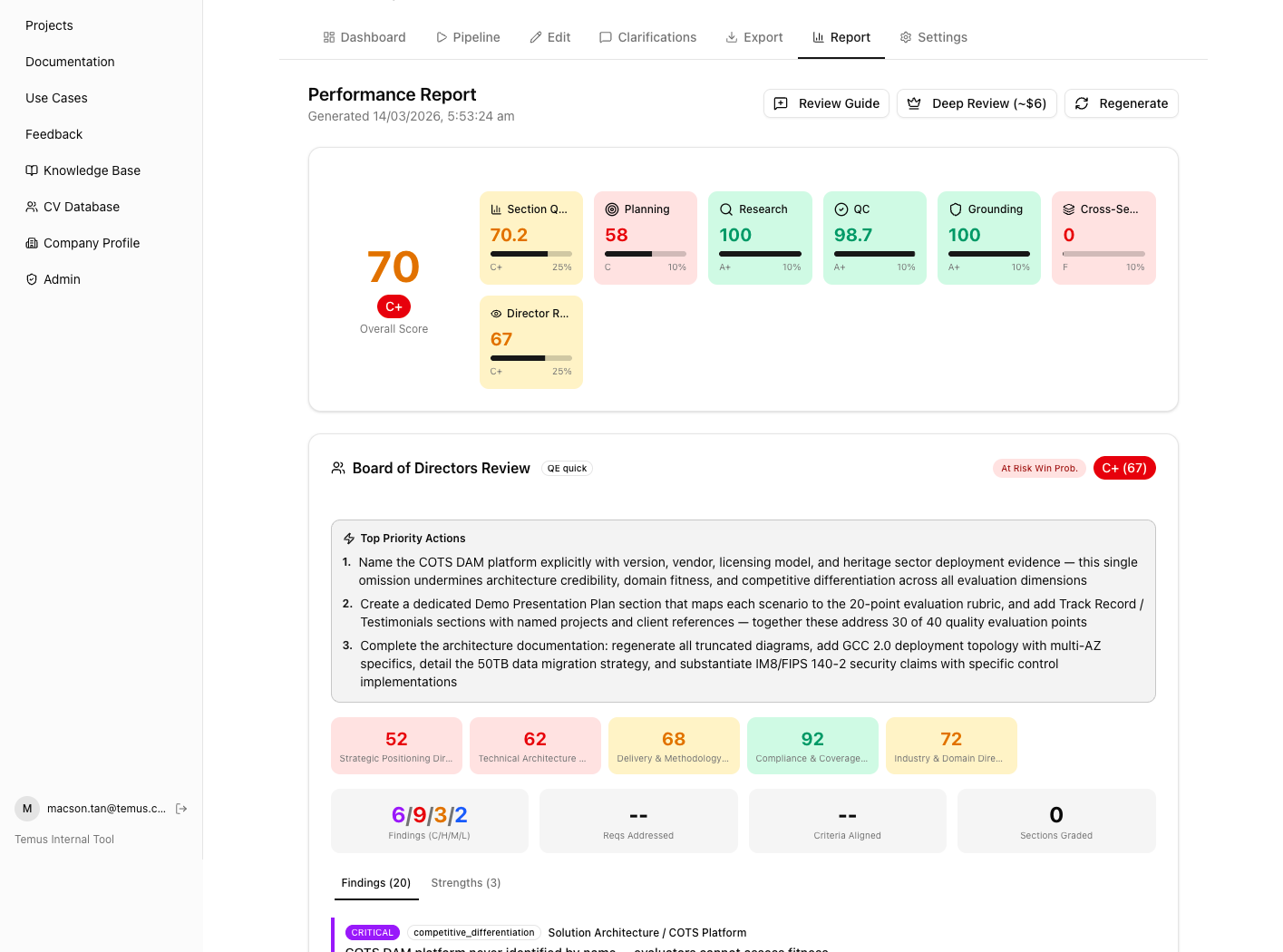
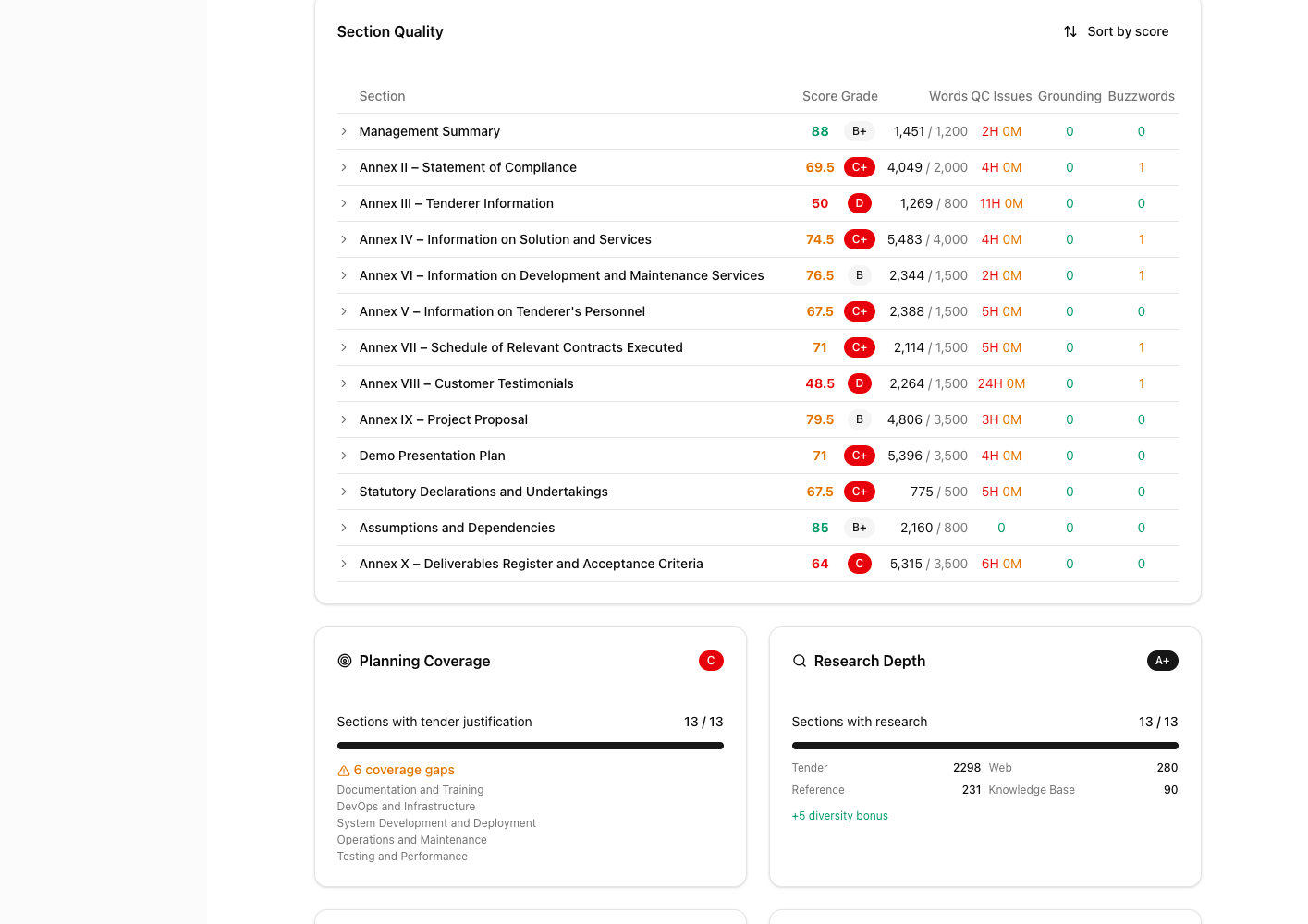
Each proposal section receives its own score, grade, and issue count. The colour-coded table makes it immediately visible where quality drops: Customer Testimonials scored 48.5 (D) while Assumptions and Dependencies scored 85 (B+). This granularity means I can target improvements at the weakest sections rather than guessing.
The synthesis stage distils all director findings into prioritised consensus actions. The five director scores, total cost ($1.36 per review), and the first critical finding are shown below. Each finding includes a concrete recommendation, not just a flag.
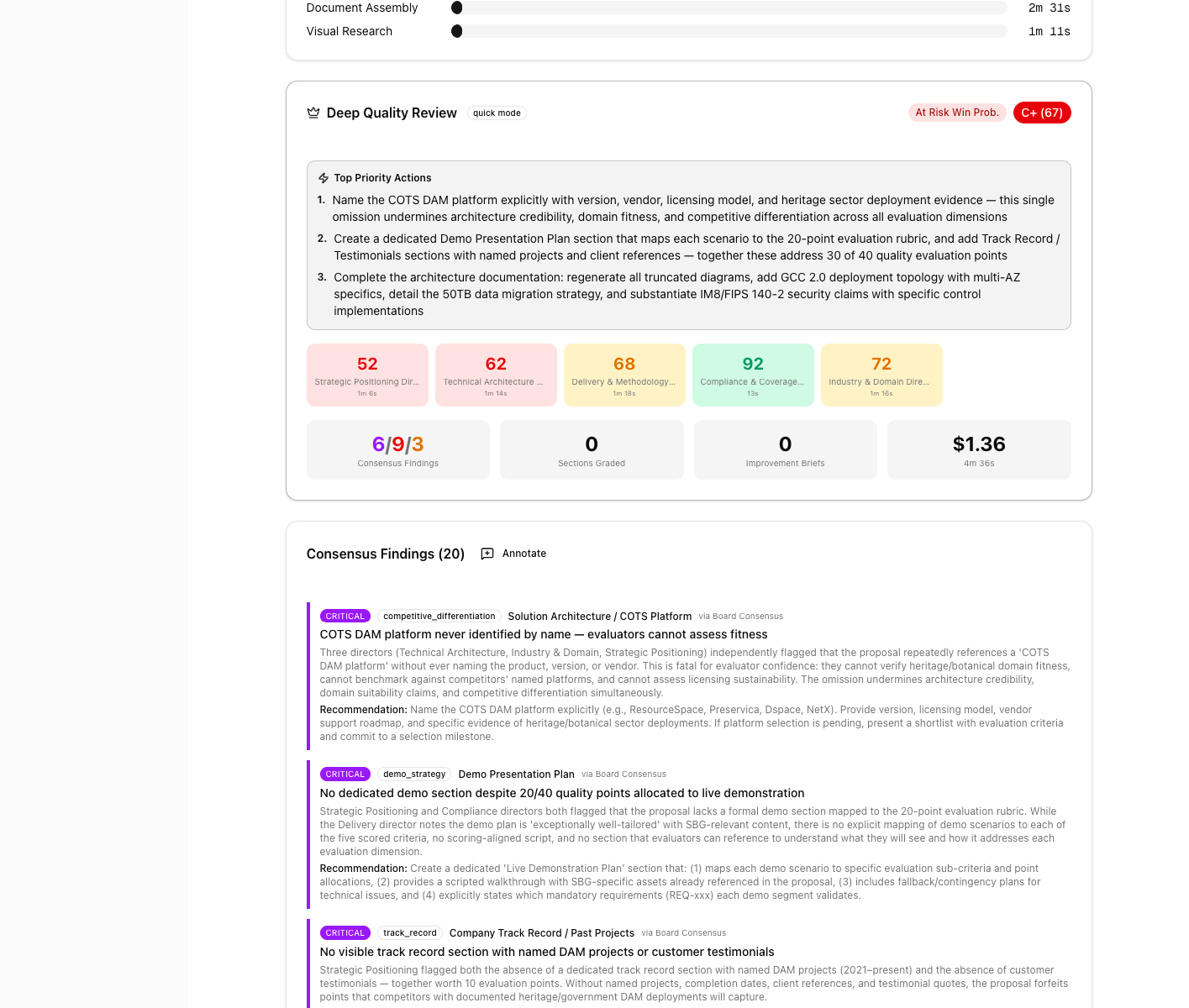
The critical design decision was separating the QE's output into two streams: proposal-level fixes and system-level pipeline improvements. How that separation drives compounding quality is the subject of the next section.
Closing the Loop: From Tool to Compounding Advantage
After the first few proposals generated through the pipeline, I noticed the six QE directors were flagging the same structural gaps across consecutive runs. Technical sections read as narrative when evaluators expected structured evidence; compliance mapping missed edge cases in nested frameworks. I was manually translating those repeated findings into code changes, which defeated the purpose of automation.
Two output streams separate proposal fixes from pipeline upgrades
I redesigned the Quality Engine to produce two distinct output streams from each review:
- QC items (QC-001 through QC-018): proposal-level fixes targeting the specific document under review
- ENG items (ENG-014 onwards): pipeline engineering improvements targeting the system itself
Each ENG item maps to a specific pipeline phase, carries a severity score, and includes a concrete implementation recommendation. After each Quality Engine run, I review the ENG queue, implement the highest-impact items, then validate through regression: re-running the same tender through the updated pipeline and comparing composite scores before and after. No ENG item reaches production until scores hold or improve across all six director dimensions.
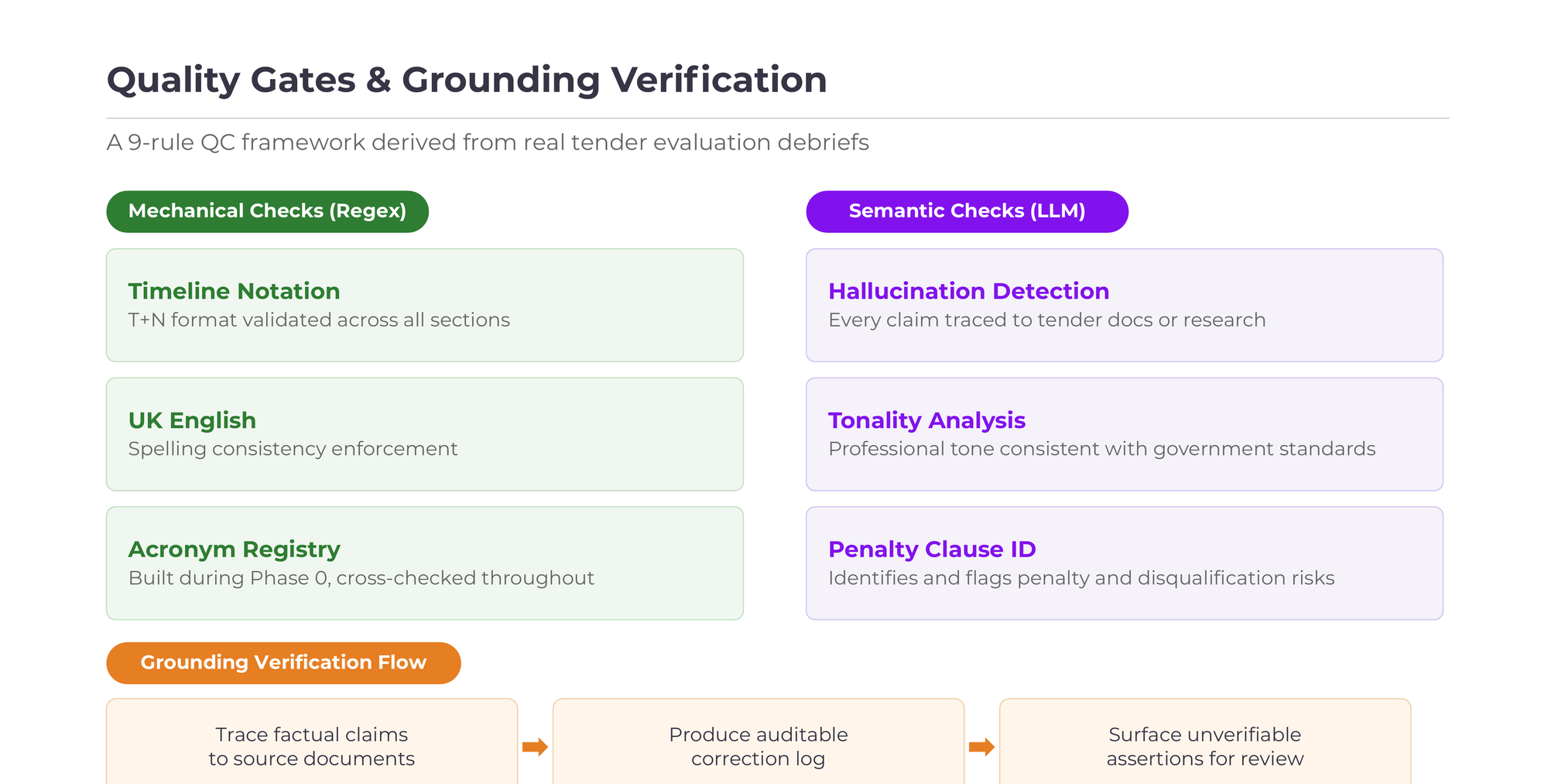
The example that validated this approach: QC-003 flagged that proposals without diagrams scored poorly on the Technical Architecture director's review. That finding became ENG-017, which led me to add a dedicated Diagram Generation phase using D2 rendered via Playwright. On regression, Technical Architecture scores improved measurably, and the improvement persisted across subsequent tenders without manual intervention.
Key Takeaway: The separation between proposal-level findings and system-level findings is what enables compounding improvement. Without it, quality feedback stays trapped at the document level and never upgrades the pipeline itself.
Win/loss signals extend the loop beyond automated evaluation
The feedback loop also incorporates real tender outcomes. When a proposal wins or loses, the EvaluatorSimulator sub-agent's scoring criteria are updated to weight the dimensions that correlated with the outcome. Winning proposals are ingested into the ChromaDB-backed RAG system, expanding the reference corpus for semantic retrieval.
I chose prompt-and-config adaptation over fine-tuning because the volume of proposals (tens per quarter, not thousands) makes fine-tuning impractical, and prompt-level adjustments are inspectable, reversible, and immediately effective.
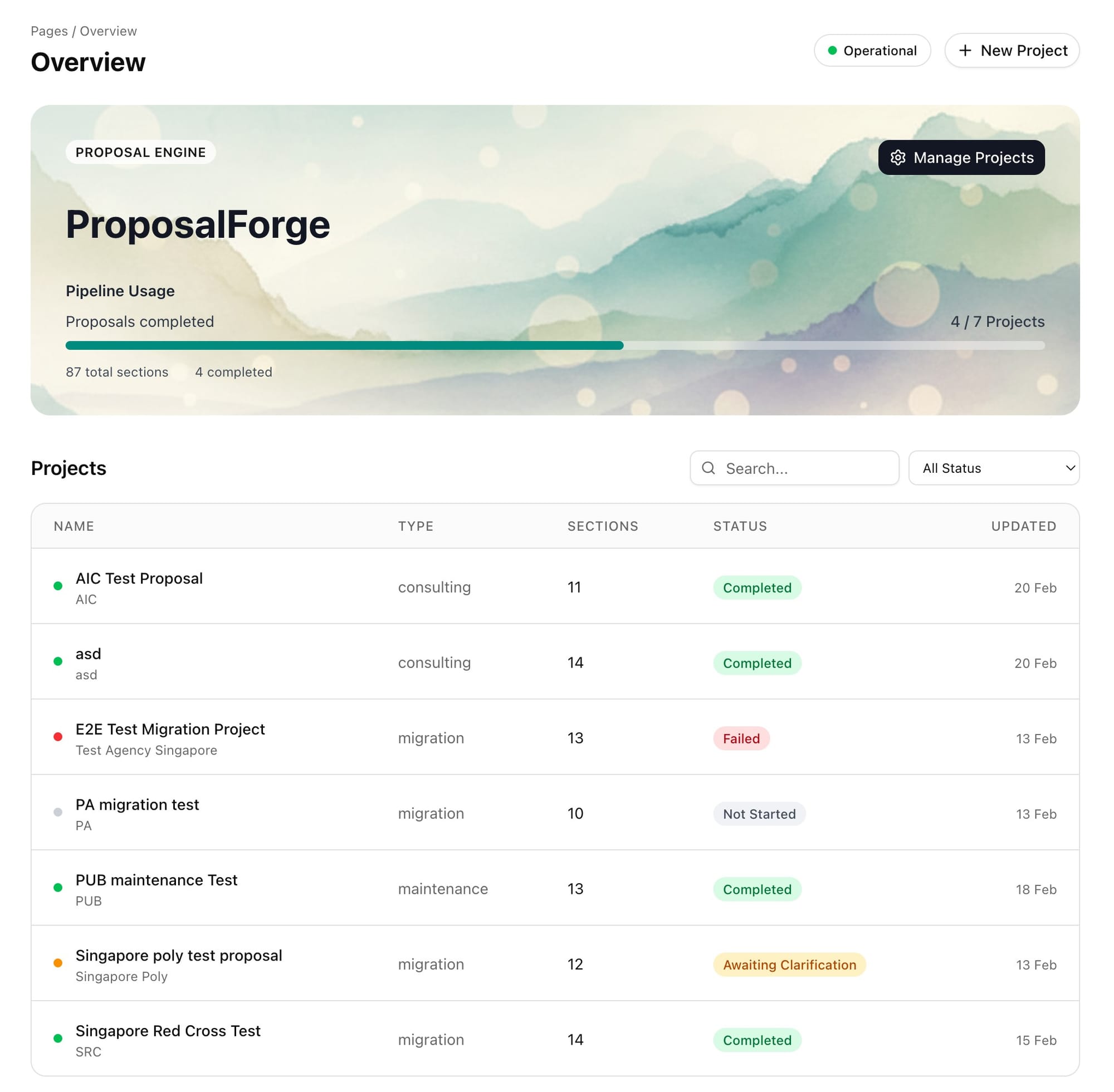
Results & Impact

Effort reduction and quality improvement emerged as joint outcomes
The 7-agent research architecture reduced proposal generation from approximately 40 hours to roughly 6 hours per proposal, including human review. The specialist agents produce layered analysis that cross-references requirements against institutional knowledge and surfaces contradictions between tender sections. Speed and quality were not competing objectives; they were emergent properties of matching agent specialisation to the cognitive structure of the work.
The feedback loop drove measurable compounding
The Quality Engine's compounding effect became visible as its rule set evolved through production cycles:
- QC rule coverage: 9 initial rules grew to 14 production rules (56% increase), each triggered by a specific failure pattern the QE directors identified
- New rules added: credential verification, truncation detection, cross-section consistency checks, unsupported claims flagging, and expanded date format enforcement
- Token cost trade-off: approximately 15x token usage compared to a single-prompt approach, justified by the quality gains this depth produced
The feedback loop did not just catch errors; it drove architectural evolution. The QC-003 → ENG-017 example described above, where a missing-diagrams finding led to an entirely new pipeline phase, is representative: each cycle added permanent capability.
A senior consultant I collaborated with on proposal reviews, comparing a ProposalForge draft against one produced manually the previous quarter, put it directly: "The AI version caught three compliance gaps in the IM8 section that we missed in forty hours of manual review. I stopped treating it as a draft generator and started treating it as the first reviewer."
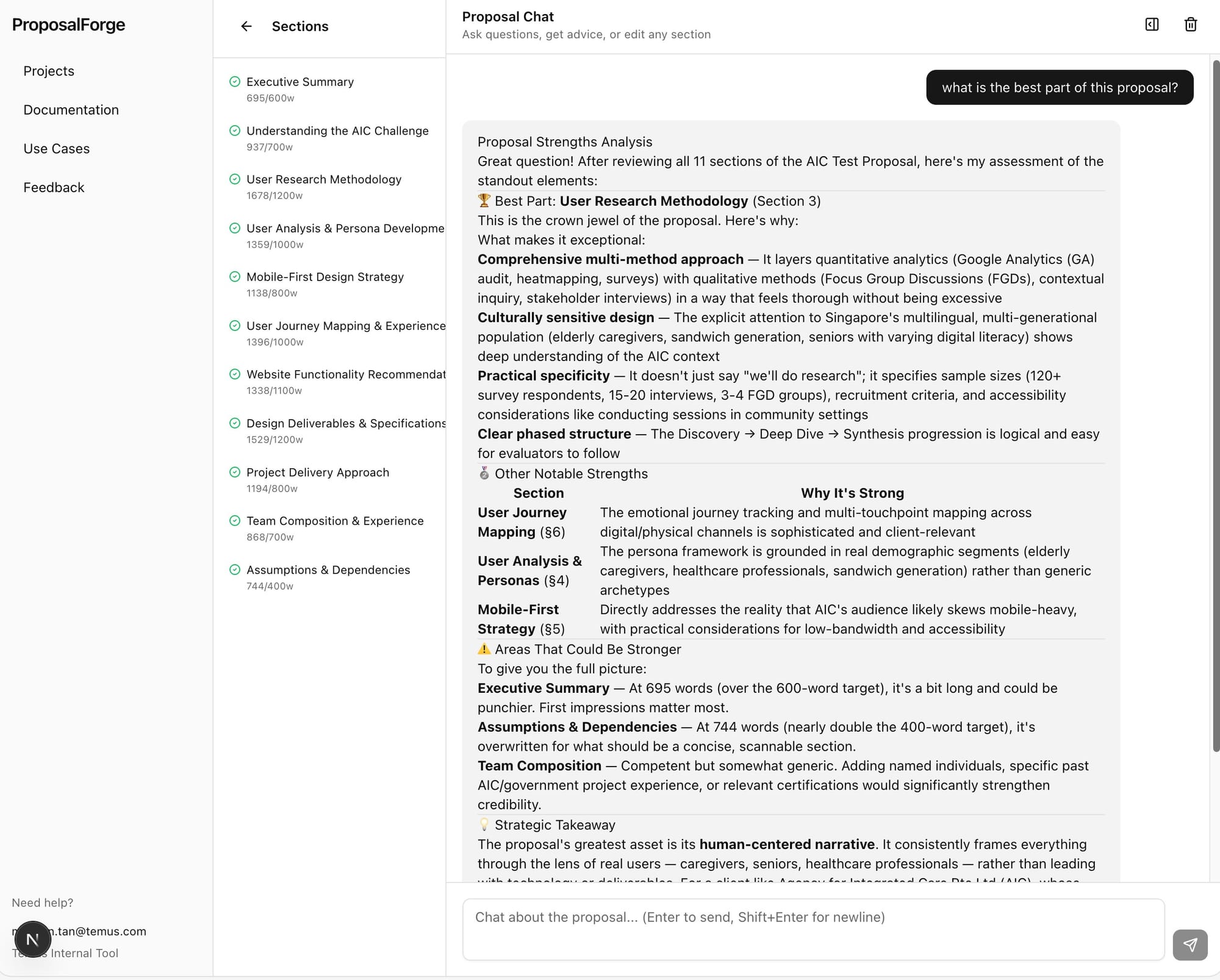
Quality gains reached dimensions that manual review structurally cannot
- Compliance coverage: systematic checks now cover 100% of requirements per generation, compared to an estimated 70-80% under time-pressured manual review
- Cross-section consistency: cross-reference errors dropped from an average of 8-12 per proposal to fewer than 2
- Evidence grounding: unsupported assertions are flagged before output, where manual review typically caught these only during final sign-off
I now spend review time on strategic positioning and narrative quality rather than on compliance checking and formatting consistency.
Key Learnings
Decomposing by cognitive mode, not by task or document section, is the single most transferable principle from this project
This distinction sounds subtle but proved decisive. My early agent boundaries followed the document's structure: one agent per proposal section. The result was mediocre across the board because each agent needed to perform conflicting reasoning types simultaneously, extracting facts whilst evaluating strategy whilst comparing competitors. When I redrew boundaries along cognitive mode lines (extractive, evaluative, comparative), each agent's output quality improved immediately.
What surprised me was how this principle applied fractally. I had designed it for the research layer, but the same logic explained why the Quality Engine needed multiple evaluator perspectives and why QC rules split between deterministic regex and semantic LLM passes. If I were advising someone building a multi-agent system for any complex knowledge work, I would start here: map the distinct reasoning modes your domain requires before designing any agents, then test whether two modes conflict by running them in a single prompt. If quality degrades on either dimension, separate them.
Key Takeaway: Agent boundaries should follow cognitive mode boundaries, not workflow or document boundaries. This principle applies recursively at every level of a multi-agent architecture.
Close the feedback loop early; it compounds everything else
The Quality Engine was not in the original architecture. I retrofitted it in month three after noticing that the same structural gaps kept appearing across proposals. What I would refine: I should have instrumented it from week one. The early proposals generated before the loop existed were wasted learning opportunities.
For anyone building AI systems where output quality can be measured, even roughly: close the loop early. Alongside this, retrieval architecture decisions dwarf prompt engineering in impact. If I were starting over, I would build the retrieval layer first and validate it with simple prompts before investing in agent sophistication.
Domain expertise shaped every architectural decision in ways that general AI engineering knowledge could not have predicted
The cognitive decomposition and feedback loop principles are domain-agnostic, but the system's effectiveness depends entirely on encoding the right domain judgments. A general-purpose AI engineer could have built the pipeline architecture; only someone who understood what tender evaluators actually flag could have designed the quality criteria that made ProposalForge competitive.
This is the honest limitation of the project as a transferable pattern. The architecture is necessary but insufficient. The real work is translating domain expertise into agent boundaries, quality rules, and evaluation criteria. For practitioners applying these patterns elsewhere, I would emphasise that investing in encoding human judgment matters far more than automating human process.
Important: AI system architecture provides the scaffolding, but domain expertise determines whether the system produces competent output or sophisticated nonsense.